
این نوشته، بخشی از مجموعه مقالات «یادگیری ماشین» است که به زبان ساده، برای مدیران، اهالی کسبوکار و مارکتینگ، مدیر محصولها و توسعهدهندهها نوشته شده است. اینجا را کلیک کنید تا به فهرست کلی مقالات بروید.
در نوشتهٔ قبل، درباره کاهش ابعاد داده یا عصارهگیری از دادهها صحبت کردیم. اجازه دهید این نوشته را با یک مثال ملموس در این رابطه شروع کنیم.
فرض کنید میخواهیم ترافیک بخشی از یک خیابان را در یک ساعت خاص پیشبینی کنیم. برای آموزش مدل، دادههای متنوعی را برداشت کردهایم؛ مثلا تعداد ماشینهای عبوری در ۵ دقیقه گذشته، میانگین سرعت ماشینها، درجه و وضعیت آبوهوا، روز هفته، ساعت روز، تعطیل بودن یا نبودن، آلودگی هوا و … .
هر نمونه را با یک بردار نشان میدهیم:
x = [57, 83, 1, 4, 0, 1, ...]در بردار بالا، عدد ۵۷ مثلا میتواند نماینده تعداد ماشینهای عبوری و ۸۳ نشاندهنده میانگین سرعت ماشینها باشد. این بردار ممکن است کوچک به نظر برسد. اما اگر بخواهیم در هر دقیقه، برای هر نقطه از شهر، این دادهها را جمعآوری کنیم، پردازش آنها پرهزینه میشود.
وقتی تعداد ماشینهای عبوری را داریم، شاید میزان آلودگی هوا چیز بیشتری درباره ترافیک در اختیار مدل ما قرار ندهد. اما از کجا بدانیم کدام ویژگی را میشود دور ریخت؟
در یادگیری با نظارت، ما به پاسخ یا خروجی مطلوب دسترسی داشتیم. مثلا میدانستیم که در روزهای گذشته، دمای هوا چه تاثیری بر میزان فروش بستنی گذاشته است. اینجا اما تصویری از وضعیت مطلوب نداریم.
به همین خاطر، روشهای کاهش ابعاد داده، اغلب در دسته «یادگیری بدون نظارت» قرار میگیرند. در یادگیری بدون نظارت، خبری از دادههای برچسبدار (labeled data) نیست؛ یعنی مشخص نیست که به ازای مجموعهای از ویژگیهای ورودی، مدل چه خروجیای باید تولید کند.
بنابراین ما باید مسئله را به گونهای تعریف کنیم که دستیابی به پاسخ مطلوب، بدون راهنمایی (دادههای برچسبدار) امکان پذیر شود. یک روش شناختهشده برای عصارهگیری از دادهها، Principal Component Analysis است. PCA تلاش میکند مولفههای اصلی دادهها را به گونهای بیرون بکشد که واریانس آنها بیشینه شود.
برای درک موضوع، فرض کنید که ما ۵۰۰ جمله داریم که مفاهیم مختلفی را بیان میکنند. میخواهیم عصاره این جملات را بگیریم، بدون اینکه هیچ مفهومی از دست برود. پس باید جملاتی را حذف کنیم که مفاهیم مشابهی را بیان میکنند. در این صورت، جملات باقیمانده، مفاهیم مستقل و منحصربهفردی خواهند داشت؛ این یعنی واریانس دادهها بیشینه شده است.
PCA با دادههای برداری، به شکل مشابه رفتار میکند. روش کار PCA، شبیه به درست کردن اسپرسو است؛ یعنی مولفههای اصلی داده را بهگونهای استخراج میکند که با دادههای اولیه (پودر قهوه) شباهتی ندارد. بنابراین بردار بالا بعد از عصارهگیری، ممکن است تبدیل شود به:
x' = [40, 1, 102]مثالهای دیگری از یادگیری بدون نظارت
فرض کنید برخی از رانندگان یک تاکسی اینترنتی، با انجام سفرهای جعلی، از طرحهای تشویقی سوء استفاده میکنند. در اینجا ما تعریف دقیقی از سفر جعلی نداریم. یعنی نمیدانیم چه رفتاری از طرف رانندگان، نشانه تقلب است.
به طور کلی، تشخیص ناهنجاریها و الگوهای خاص و پنهان شده در دادههای بدون برچسب (unlabeled)، در دسته «یادگیری بدون نظارت» قرار میگیرد. یادگیری بدون نظارت، سنگبنای مدلهای مولد هوش مصنوعی مثل ChatGPT هم هست.
خوشهبندی
همه ما بارها با پیشنهادات خرید در فروشگاههای آنلاین روبهرو شدهایم. برای ارائه این پیشنهادات، فروشگاههای آنلاین اغلب مشتریان خود را براساس شباهتهایشان، گروهبندی میکنند.
سایتهای بخش آنلاین فیلم و سریال همانند نتفلیکس، با استفاده از همین تکنیک، کاربران را براساس سلایقشان و محتوای ویدیویی را براساس مضامینی که دارند، در چندین گروه قرار میدهند. براساس این گروهبندی، این سایتها به شما محتوایی را پیشنهاد میدهند که احتمالا موردپسندتان است.
خوشهبندی یعنی قرار دادن دادهها در چند گروه به شکلی که اعضای خوشه، به یکدیگر شباهت زیادی داشته باشند. برای خوشهبندی دادهها، باید تعریف کنیم که منظورمان از «شباهت» چیست.
مثلا پمپبنزینهای شهر واشنگتن را در نظر بگیرید. در تصویر زیر، هر ضربدر نماینده یک پمپبنزین است:

میتوانیم این پمپبنزینها را براساس «نزدیکی»شان به یکدیگر، درون چند خوشه قرار بدهیم. اگر بخواهیم ۵ خوشه داشته باشیم، نتیجه چیزی شبیه به تصویر زیر میشود:
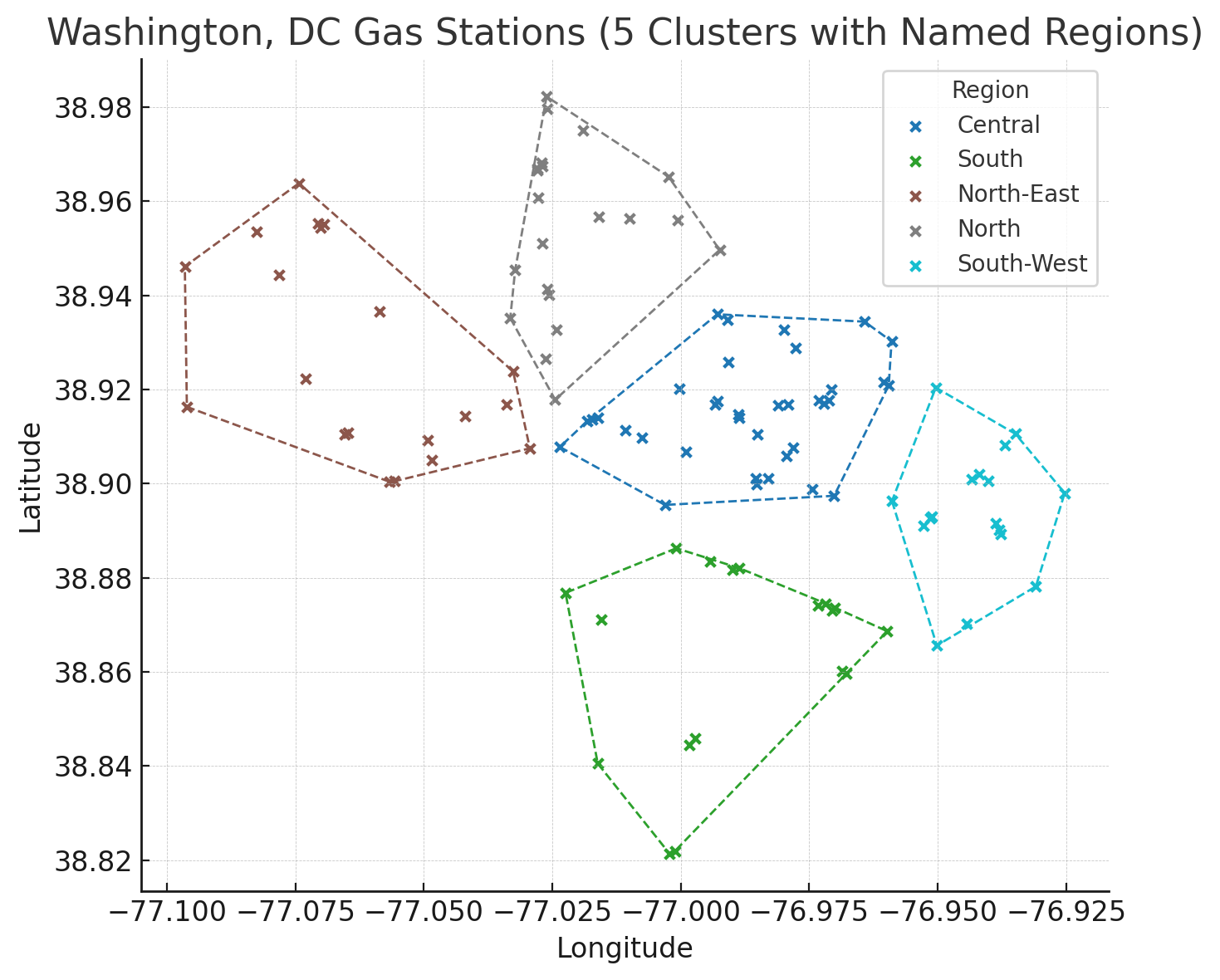
در اینجا برای خوشهبندی پمپبنزینها، از الگوریتم K-Means استفاده کردهایم که از پرکاربردترین روشها در خوشهبندی است. در مثال بالا، این الگوریتم ۵ پمپبنزین را به صورت تصادفی، به عنوان مرکز خوشهها در نظر میگیرد و هر پمپبنزین را به خوشهای نسبت میدهد که به مرکز آن بیشترین شباهت را داشته باشد (فاصله نزدیکتری داشته باشد).
سپس میانگین اعضای گروه، به عنوان مرکز خوشه انتخاب میشود. به همان صورت قبلی، پمپبنزینها به خوشههای جدید نسبت داده میشوند. این کار به قدری تکرار میشود که دیگر اعضای خوشهها تغییر نکند.
اگر تعداد خوشهها را تغییر دهیم (مثلا ۷ تا)، نتیجه متفاوت میشود:
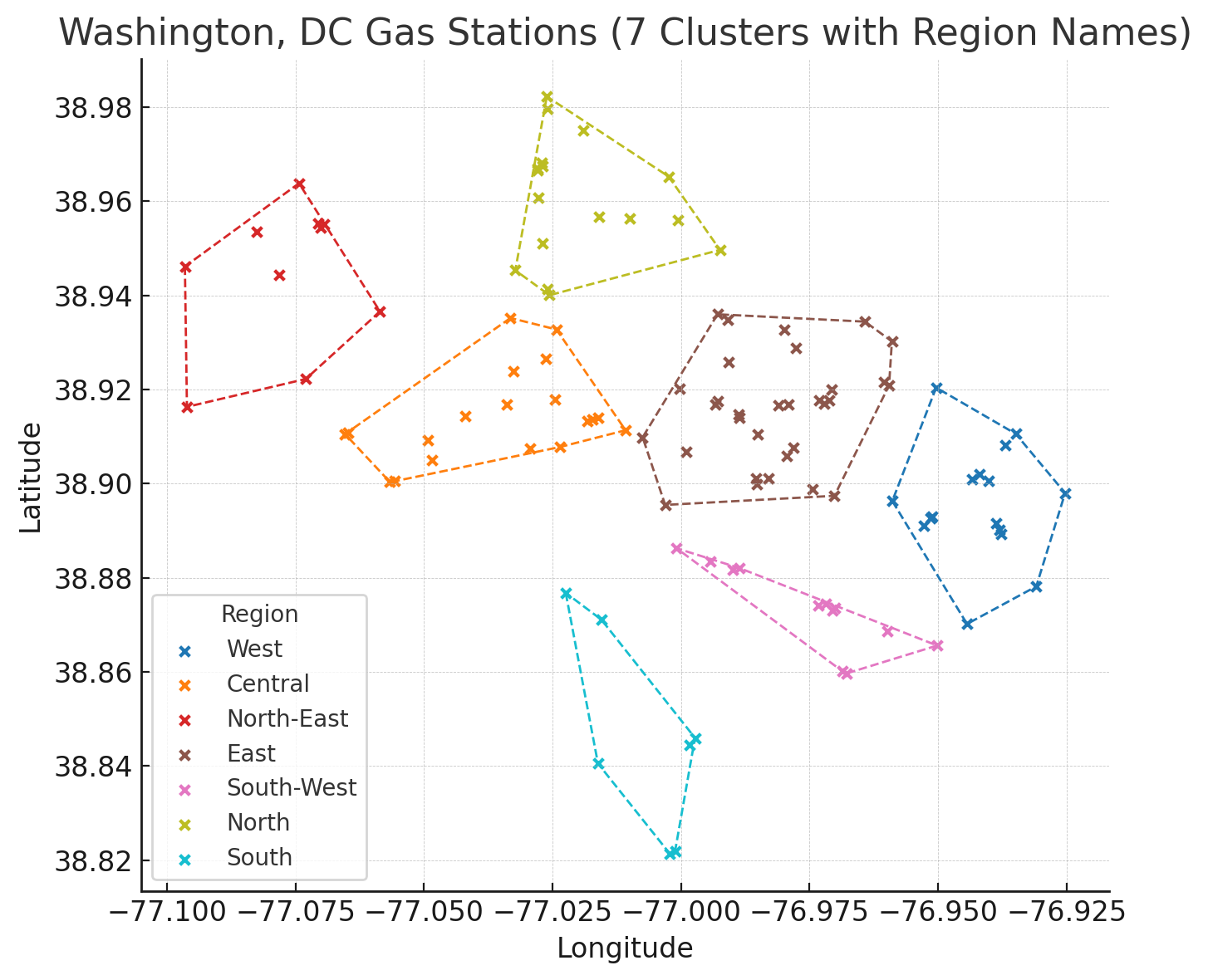
در اینجا، ما فقط مشخص کردیم که منظورمان از شباهت، نزدیکی جغرافیایی است؛ روی نحوه شکلگیری خوشهها نظارتی نداشتیم. به همین خاطر «خوشهبندی» ذیل «یادگیری بدون نظارت» قرار میگیرد.
البته، اگر از الگوریتم متفاوتی برای خوشهبندی استفاده کنیم، ممکن است نتیجه به شدت متفاوت شود.
کلیدواژههای مهم
بعد از خواندن این مطلب، سعی کنید این کلیدواژهها/مفاهیم را به خاطر بسپارید:
- یادگیری بدون نظارت | Unsupervised Learning
- تحلیل مؤلفههای اصلی | Principal Component Analysis
- خوشهبندی | Clustering
- K-Means
آنچه خواندید، بخشی از سلسله مطالبی درباره یادگیری ماشین است. این نوشتهها مخصوص مدیران و افراد غیرفنی است که میخواهند، بدون ورود به جزئیات، از هوش مصنوعی و یادگیری ماشین سر در بیاورند.
میتوانید به نوشته قبلی برگردید و درباره «مهندسی ویژگیها و کاهش ابعاد داده» بخوانید. همچنین میتوانید نوشتهٔ «یادگیری با نظارت» را مرور کنید. در نوشتههای بعدی، این مباحث را ادامه خواهم داد.
نوشتههای روزانه من را درباره محصول، فناوری و کسبوکار در تلگرام دنبال کنید!
دیدگاهتان را بنویسید