
این نوشته، بخشی از مجموعه مقالات «یادگیری ماشین» است که به زبان ساده، برای مدیران، اهالی کسبوکار و مارکتینگ، مدیر محصولها و توسعهدهندهها نوشته شده است. اینجا را کلیک کنید تا به فهرست کلی مقالات بروید.
در نوشته قبلی، با شبکه عصبی آشنا شدیم. حالا میدانیم که اگر یک شبکه عصبی را به اجزای سازنده آن – یعنی نورونها – بشکنیم، با تعدادی تابع روبهرو خواهیم شد.
انواع لایهها در شبکه عصبی
شبکه عصبی با گراف نمایش داده میشود. گرافها کمک میکنند درک بهتری از ارتباط نورونها و نحوه عملکرد شبکه عصبی داشته باشیم. میدانیم که خروجی هر لایه در این شبکه، به دست لایههای بعدی میرسد و این کار آنقدر ادامه پیدا میکند تا در لایه پایانی – که به آن لایه خروجی یا Output Layer میگوییم – خروجی نهایی شبکه تولید شود.
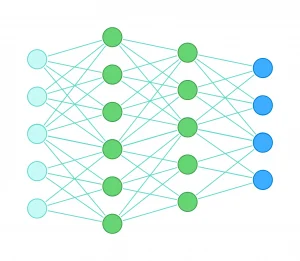
همچنین به لایه سمت چپ، لایه ورودی یا Input Layer میگوییم؛ جایی که دادههای آموزشی وارد شبکه میشوند. در بین این دو لایه که ما مستقیم با آنها تعامل داریم، تعدادی لایه پنهان یا Hidden Layer وجود دارد؛ این لایهها شبیه به خمیر بازیای هستند که ماشین به آنها شکل میدهد و از محدودیتهای ذهنی ما فراتر میرود.
رابطه بین لایهها
کشیدن یک گراف اگرچه سودمند است، اما ممکن است ما را از نوع ارتباطی که توابع با یکدیگر دارند غافل کند. ما نورونها را پشت سر هم میکشیم تا شیوه اتصال آنها را به هم نشان دهیم. یک روش دیگر این است که آنها را به عنوان توابع تو در تو نمایش دهیم.
در تصویر زیر، چند ماهی میبینیم که توسط یکدیگر بلعیده شدهاند؛ هر ماهی، توسط یک ماهی بزرگتر از خودش! این تصویر میتواند روابط لایههای شبکه عصبی را به شیوهای دیگر نشان دهد. هر ماهی، محتویات ماهی دیگر را در دل خودش دارد؛ شامل ماهیهایی که از قبل بلعیده:
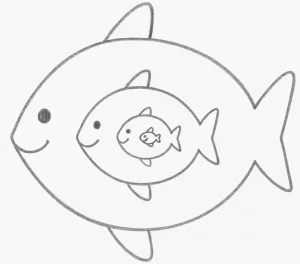
اگر هر ماهی، نماینده یک لایه از شبکه عصبی باشد، کوچکترین ماهی، معادل لایه ورودی است. لایههای پنهان، یکی پس از دیگری ماهیهای قبلی را میخورند تا آنجا که بزرگترین ماهی – همان لایه خروجی – همه ماهیها را در دل خودش جای دهد.
البته در این تشبیه، اندازه ماهیها نباید شما را گمراه کند. این مثال چیزی درباره اندازه لایهها نمیگوید؛ صرفا تصویر متفاوتی از ارتباط لایهها میسازد.
ارتباط نورونهای شبکههای عصبی به زبان ریاضی، اینطور نشان داده میشود:
f(g(x))اگر f و g دو تابع باشند، در اینجا f ماهی بزرگتر و g ماهی کوچکتر است که خروجیاش، به f تحویل داده میشود. مثال ماهیها را در گوشهای از ذهنتان نگاه دارید تا به آن برگردیم.
آموزش به شبکه عصبی
برای آشنایی با نحوه آموزش شبکه عصبی، ابتدا باید برخی از موضوعاتی را مرور کنیم که پیشتر به آن پرداختهام.
در نوشته چاقوی سوئیسی یادگیری ماشین، گفتیم که دیتا ساینتیستها برای آموزش به ماشین، هر موضوعی را تبدیل به یک «مسئله بهینهسازی» میکنند. مثلا در یادگیری با نظارت، به ازای دادههای ورودی (مثل درجه هوا)، خروجی مطلوب را به ماشین نشان میدهند (مثل میزان فروش بستنی) و از ماشین میخواهند وزنها را طوری انتخاب کند که صرفا با داشتن داده ورودی، بشود خروجی مطلوب را تخمین زد یا محاسبه کرد.
ماشین چطور وزنها را انتخاب میکند؟ در ابتدای راه، با آزمون و خطا. سپس هر انتخاب ماشین، منجر به تولید یک خروجی میشود. تابعی موسوم به «تابع زیان» اختلاف خروجی تولید شده را با خروجی مطلوب میسنجد و به ماشین بازخورد میدهد. اگر این اختلاف ناچیز باشد، یعنی ماشین کارش را خوب انجام داده. در غیر این صورت، ماشین باید وزنها را بهبود دهد.
برای بهبود وزنها، گفتیم که ماشین یک قطبنما دارد که آن را در انتخابهای بعدی راهنمایی میکند. نام این قطبنما را «گرادیان کاهشی» گذاشتهاند؛ همان چاقوی سوئیسی خودمان!
الگوریتم پسانتشار یا Back propagation
آنچه شبکه عصبی را متمایز میکند، پیچیدگی ناشی از تو در تو بودن آن است. بر خلاف مثالهای قبلی، ما دیگر با یک تابع منفرد رو به رو نیستیم. بلکه ممکن است شبکهای داشته باشیم از چند هزار نورون. چطور میتوانیم شبکهای از هزاران تابع در هم تنیده را آموزش دهیم؟
پاسخ، «الگوریتم پسانتشار» است. این الگوریتم، «چاقوی همهکاره» را در مشتش میگیرد و از آخرین لایه شبکه عصبی شروع به حرکت میکند. در مسیر حرکت، مشخص میکند که هر وزن چقدر باید تغییر کند تا شبکه پاسخهای بهتری تولید کند. شاید بپرسید چرا از لایه آخر؟
برای پاسخ، باید به تصویر ماهیهای بلعیده شده برگردیم. وقتی توابع خروجیهای یکدیگر را میبلعند، ما به ماهی بیرونی دسترسی داریم. چاقوی سوئیسی با بزرگترین ماهی – یعنی لایه خروجی – شروع میکند و با شکافتن هر ماهی، به لایههای قبلتر میرود.
آنچه شرح دادم، استعارهای است از یک قاعده ساده در مشتقگیری که در محاسبه گرادیان به آن نیاز داریم. مثل همیشه، قصد ندارم به جزئیات ریاضیاتی موضوع بپردازم. تنها به گفتن این بسنده میکنم که هنگام مشتق از توابع تو در تو، به شکل سلسلهمراتبی از توابع مشتق میگیریم؛ شبیه به سلسلهمراتب شکافتن شکم ماهیها.
مرحلهٔ پیشخور کردن یا Feed Forward
بیایید به استعاره ماهیها برگردیم. پیش از اینکه الگوریتم پسانتشار، کارش را از ماهی بزرگتر – یا لایه آخر – شروع کند، ابتدا باید ماهیها، به ترتیب اندازه، یکدیگر را بلعیده باشند. به این مرحله، «پیشخور کردن» میگویند.
در Feed Forward، وزنها در دادههای ورودی ضرب میشوند و نتیجه مرحله به مرحله، به لایه بعد منتقل میشود تا در نهایت به لایه خروجی برسیم؛ اینجا دیگر ماهی بزرگتر، خروجی لایههای قبلی را بهکلی بلعیده است.
خلاصه نحوه آموزش به شبکه عصبی
همه آنچه گفتم را میشود در چند مرحلهٔ شستهرفته، خلاصه کرد:
- وقتی آموزش شبکه شروع میشود، وزنهای شبکه (که به آنها پارامتر هم میگویند) اغلب به صورت تصادفی، مقداردهی میشود.
- پیشخور کردن شروع میشود. در هر لایه، وزنها در مقادیر ورودی ضرب شده و حاصلجمع آنها، به لایه بعدی تحویل داده میشود. در نهایت در لایه آخر، به خروجی شبکه میرسیم.
- تابع زیان، اختلاف خروجی محاسبه شده را با خروجی مورد انتظار (که در دادههای آموزشی وجود دارد)، میسنجد. اگر مورد قبول نباشد، به مرحله بعد میرویم.
- الگوریتم پسانتشار ، از لایه خروجی (ماهی بزرگتر) به سمت لایه ورودی، شروع به کار میکند و با اصلاح وزنهای (پارامترهای) هر لایه، تلاش میکند خروجی شبکه را به مقدار مطلوب نزدیکتر کند.
- دوباره به مرحله ۲ باز میگردیم.
بنابراین برای اینکه یک بار کل وزنهای گراف را بهبود دهیم، ۲ مرحله محاسباتی طی میشود: یک بار Feed Forward و یک بار Back Propagation. این کار به قدری تکرار میشود تا مدل یاد بگیرد خروجی موردنظر را تولید کند.
هزینه آموزش به شبکه عصبی
با افزایش تعداد نورونهای یک شبکه، تعداد پارامترها یا همان وزنهای شبکه عصبی به شکل نمایی افزایش مییابد. زیرا هر نورون میتواند به تمامی نورونهای لایه قبل یا بعد از خودش وصل شود.
مثلا اگر لایه ورودی ۴ هزار نورون و لایه بعد از آن ۱۴ هزار نورون داشته باشد، ۵۶ میلیون پارامتر از اتصال این نورونها به یکدیگر پدید میآید:
4,000 × 14,000 = 56,000,000 حالا تجسم کنید چندین لایه داشته باشیم و هر لایه، هزاران نورون. در فرایند یادگیری، هر بار که وزنهای شبکه عصبی را بهروز میکنیم، یک بار مرحله Feed Forward انجام میشود و یک بار Back propagation. این یعنی هر بار بهروزرسانی پارامترها، نیازمند میلیونها، بلکه میلیاردها «جمع و ضرب» است.
یادگیری عمیق
تعداد نورونهای شبکه را میتوان به دو شکل افزایش داد: استفاده از نورونهای بیشتر در هر لایه یا استفاده از لایههای بیشتر. تحقیقات نشان داده که افزایش تعداد لایه، تاثیرگذارتر است. زیرا افزایش لایه، یعنی خلق ماهی بزرگتری که خروجی لایه قبلی را میبلعد. ریختن نتیجه محاسبات توابع در دل توابع دیگر، آنها را قدرتمندتر میکند.
در ابتدا، عمق شبکههای عصبی بسیار کم بود. مثلا با یکی دو لایه، مدلی را آموزش میدادند. در طول زمان، اهمیت تعداد لایههای بیشتر در مرکز توجه محققان قرار گرفت و مفهوم «یادگیری عمیق» پدیدار شد. یادگیری عمیق اشاره به شبکههای بیاعصابی دارد که تعداد لایههای آنها زیاد است.
کلیدواژههای مهم
بعد از خواندن این مطلب، سعی کنید این کلیدواژه را به خاطر بسپارید:
- لایه ورودی | Input Layer
- لایه پنهان | Hidden Layer
- لایه خروجی | Output Layer
- الگوریتم پسانتشار | Back propagation
- مرحله پیشخور کردن | Feed Forward
- یادگیری عمیق | Deep Learning
آنچه خواندید، بخشی از سلسله مطالبی درباره یادگیری ماشین است. این نوشتهها مخصوص مدیران و افراد غیرفنی است که میخواهند، بدون ورود به جزئیات، از هوش مصنوعی و یادگیری ماشین سر در بیاورند.
برای آشنایی با مباحث پایهای شبکه عصبی، پیشنهاد میکنم نوشته قبلی را بخوانید: شبکه عصبی به زبان ساده.
نوشتههای روزانه من را درباره محصول، فناوری و کسبوکار در تلگرام دنبال کنید!
دیدگاهتان را بنویسید