این نوشته، بخشی از کتاب یادگیری ماشین است.
سال ۲۰۱۲، وقتی که مسابقات ImageNet داشت برای سومین بار برگزار میشد، دنیای هوش مصنوعی دچار یک شوک عظیم شد. نام این مسابقات، برگرفته از مجموعه دادهای بود که حاوی بیش از یک میلیون عکس برچسبگذاری شده بود؛ یعنی مشخص بود که محتوای هر عکس چیست.
در این مسابقات، شرکتکنندگان باید به وسیله هوش مصنوعی یا سایر روشهای الگوریتمی، عکسها را براساس محتوا، درون دسته درست قرار میدادند. آقای هینتون به همراه دو نفر از شاگردانش (الکس کریژفسکی و ایلیا سوتسکِوِر) توانستند نرخ خطا را بیش از ۱۰ درصد کاهش بدهند. کاهش ۱۰ درصدی خطا، مثل یک بمب، دنیا را تکان داد.
آنها برای تشخیص خودکار دسته عکسها، از ابزاری استفاده کردند که پیش از این وجود داشت، اما کسی از قدرت واقعی آن آگاه نبود: یک «شبکه عصبی» ۸ لایه. قبل از بهرهگیری از شبکه عصبی، تلاش محققان برای بهبود نرخ خطا، تاثیر بسیار محدودی داشت. بهبود ۱۰ درصدی، شبیه به یک انقلاب در هوش مصنوعی بود.
آنچه در این سالها، تنور هوش مصنوعی را داغ نگه داشته، همین «شبکه عصبی» است. برای اینکه با شبکه عصبی آشنا شویم، ابتدا باید عنصر سازنده این شبکه – یعنی پرسپترون – را بشناسیم.
آشنایی با پرسپترون
بیایید موضوع این نوشته را با حل یک معادله ساده آغاز کنیم. در تصویر زیر، چه اعدادی را در مربعهای خالی بگذاریم تا معادله برقرار شود؟
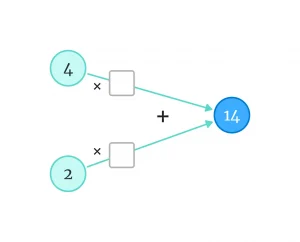
مثلا میتوانیم از اعداد ۲ و ۳ استفاده کنیم.
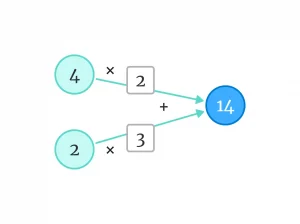
اگر اعداد را در هم ضرب کنیم، به چنین چیزی میرسیم:
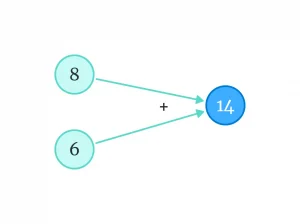
اما بیایید یک مرحله به عقب برگردیم. این بار برای سادهتر شدن شکل، علامتهای ضربدر و بهعلاوه را حذف میکنیم. اما یادمان میماند که اعداد ورودی (در اینجا ۴ و ۲) در وزنها، ضرب میشوند و حاصل آنها، با هم جمع میشود.
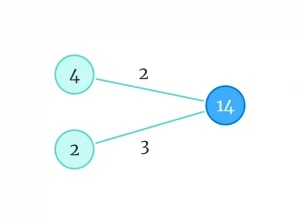
در گراف بالا، میتوانیم از وزنهای دیگری هم استفاده کنیم؛ طوری که معادله برقرار باشد. مثلا:
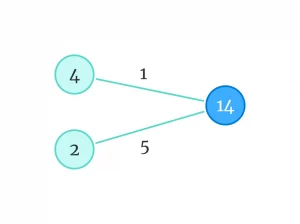
شاید کاری که کردیم، در ظاهر پیشپاافتاده به نظر برسد، اما در واقع شبیه به اتفاقی است که در یادگیری با نظارت میافتد. آنجا، ما میدانستیم به ازای یک ورودی مشخص، مدل چه خروجیای باید تولید کند. کار مدل این بود که «وزنها» را پیدا کند.
یک بار دیگر مثال پیشبینی فروش بستنی را به خاطر بیاورید. فرض کنید برای تخمین تعداد فروش، از دو متغیر «دمای هوا» و «تعداد عابرانی که در یک دقیقه از جلوی کیوسک عبور میکنند» استفاده میکنیم.
طبق دادههای آموزشی، فرض کنید در روزی که دما ۴ درجه بوده و در هر دقیقه ۲ عابر از جلوی کیوسک عبور کرده، فقط ۱۴ بستنی به فروش رسیده:
14 = (4 × w1) + (2 × w2)در یک روز دیگر، وقتی دمای هوا ۵ درجه و تعداد عابران ۱۰ نفر در دقیقه بوده، فروش به ۴۰ عدد رسیده.
40 = (5 × w1) + (10 × w2)همانطور که ما در بالا، وزنهای روی یال گرافها را حدس زدیم، وقتی یک مدل هوش مصنوعی را آموزش میدهیم، مدل هم باید جاهای خالی (w1 و w2) را پر کند:
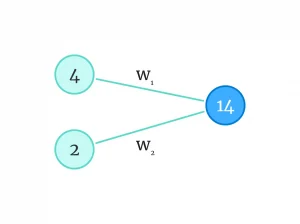
در فرآیند آموزش مدل، گرادیان کاهشی یا چاقوی همهکاره یادگیری ماشین، آنقدر مدل را به خاطر انتخابهای بدش جریمه میکند تا در نهایت، اعدادی انتخاب شوند که تعداد فروش بستنی را (به ازای هر تعداد عابر و در هر دمایی)، درست تخمین بزند.
اگر تعداد فروش بستنی را با f(x)، دمای هوا را با x1 و تعداد عابران را با x2 نشان دهیم، معادله بالا به صورت زیر در میآید:
40 = (5 × w1) + (10 × w2)
↓
f(x) = (x1 × w1) + (x2 × w2)میتوانیم این تابع یا مدل را هم روی گراف نشان دهیم:
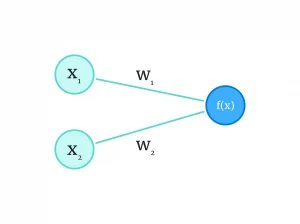
به آنچه در تصویر بالا میبینید، پرسپترون میگویند. پرسپترون یک شبکه عصبی، در سادهترین حالت ممکن است که از نورونهای بیولوژیکی انسان الهام گرفته است. براساس آنچه دیدیم، میتوانیم فعلا آن را معادل یک تابع خطی در نظر بگیریم. اما این شبکه ساده، چطور میتواند منجر به ساخت مدلهای مصنوعی پیشرفته شود؟
واقعیت این است که پرسپترونها به صورت انفرادی قدرت چندانی ندارند. قدرت آنها زمانی برملا میشود که اجتماع بزرگی از آنها بسازیم؛ یعنی به صورت مکرر، خروجی یک پرسپترون را به عنوان ورودی به یک پرسپترون دیگر بدهیم. مثلا شبکه زیر را در نظر بگیرید؛ این شبکه ۴ لایه است و بدون در نظر گرفتن لایههای ورودی و خروجی، ۱۱ نورون دارد که با رنگ سبز نشان داده شدهاند.
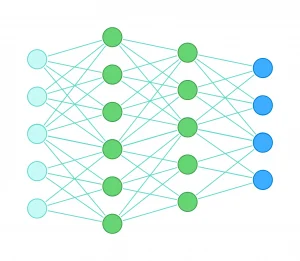
در شبکه بالا، تعداد وزنها (یالها) بسیار بیشتر است. این یعنی در فرایند یادگیری، مدل میتواند تعداد بیشتری جای خالی را پر کند. این دست مدل را برای حل مسائل پیچیدهتر، باز میگذارد؛ مثل این میماند که به یک معمار، به جای یک آجر (پرسپترون)، تعداد زیادی آجر بدهیم؛ با آجرهای بیشتر، اشکال پیچیدهتری را میتوان ساخت.
در یک شبکه عصبی بزرگ، هزاران، بلکه میلیونها نورون به یکدیگر وصل میشوند. هر پرسپترون، یک تابع کوچک است که خروجیاش، به عنوان ورودی به نورونهای دیگر تحویل داده میشود. شبکه براساس دادههای آموزشی، یاد میگیرد که چطور وزنها را مقداردهی کند تا شبکه بهترین خروجیها رو تولید کند.
در نوشتهٔ قبلی، گفتیم که ما نمیخواهیم برای ساخت توابع یا مدلهای هوش مصنوعی، به ماشین سرمشق بدهیم. زیرا این کار باعث میشود محدودیتهای ذهنی ما در طراحی توابع، به ماشینها تحمیل شود. حالا احتمالا میتوانید تصور کنید که یک شبکه عصبی، چطور محدودیتهای ذهنی ما را دور میزند.
یک شبکه عصبی بزرگ مجهز به تعداد زیادی تابع کوچک یا پرسپترون است. اگر هر تابع یک آجر باشد، شبکه هر طور که دلش بخواهد، آجرها را روی هم میگذارد. هدفش این است که با مقداردهی به وزنها، پاسخهایی را تولید کند که دقت بالایی دارد. دادههای ورودی، مسیر طولانیای از نورونها را طی میکنند و در آن سوی دیگر شبکه، تبدیل به «پاسخ» میشوند؛ بدون اینکه ما بتوانیم بفهمیم در میانه راه، چه اتفاقی برایشان افتاده.
تابع فعالسازی
بچه که بودم، در حیاط خانهمان یک نردبان کوتاه داشتیم که برای رسیدن به پشتبام کافی نبود. به ناچار باید در دو مرحله به پشتبام صعود میکردیم: اول نردبان را به دیوار تکیه میدادیم و به لبه دیوار میرسیدیم. سپس نردبان را روی لبه دیوار میگذاشتیم و میرفتیم بالا.
میشد یک نردبان بلندتر بگیریم و بالا رفتن را سادهتر کنیم؛ یا میشد چند نردبان کوچک را به هم متصل کنیم! حتی اگر چنین میکردیم، راهحل نهایی ما همچنان یک «نردبان» بود!
توابع خطی هم از این حیث، شبیه به نردبان هستند. حتی اگر هزاران تابع خطی را به یکدیگر وصل کنیم (اتصال پرسپترونها در شبکه عصبی)، خروجی همچنان یک تابع خطی میماند. انگار که یک نردبان بلندتر جایگزین نردبانهای قبلی شده باشد!
در نوشتههای قبل گفتیم که توابع خطی، برای مدلسازی مسائل پیچیده قدرت کافی ندارند. اگر قرار باشد پرسپترونها فقط نتیجه جمع و ضرب چند عدد را به عنوان خروجی تحویل پرسپترون بعدی بدهند، به چه دردی میخورد؟
به همین خاطر، پرسپترون را به یک کلید خاموش/روشن مجهز کردهاند تا دیگر یک تابع خطی ساده نباشد. اسم آن را هم «تابع فعالسازی» گذاشتهاند. این تابع روی خروجی پرسپترون مینشیند و نقش یک تصمیمگیرنده را بازی میکند. اگر کلید خاموش باشد، خروجی پرسپترون صفر میشود. این باعث میشود رفتار پرسپترون غیرخطی شود.
البته در شبکههای عصبی مدرن، از توابع فعالسازی پیچیدهتری استفاده میشود. این توابع دیگر مثل یک کلید روشن/خاموش عمل نمیکنند. شاید با اغماض بتوان رفتارشان را به یک ولوم تشبیه کرد؛ ولومی که به جای خاموش یا روشن کردن، نور خروجی پرسپترون را مشخص میکند.
«رلو»، «سگموید» و «تانژانت هایپربولیک» از توابع معروف فعالسازی هستند. در این جا قصد ندارم این توابع را معرفی کنم، اما خوب است نامشان به گوشتان خورده باشد.
کلیدواژههای مهم
بعد از خواندن این مطلب، سعی کنید این کلیدواژه را به خاطر بسپارید:
- پرسپترون | Perceptron
- تابع فعالسازی | Activation Function
- شبکه عصبی | Neural Network
نوشته حاضر، بخشی از «کتاب یادگیری ماشین» است که برای مدیر محصولها یا افراد غیرفنی نوشته شده است. فهرست این کتاب را در اینجا ببینید.
همچنین، میتوانید به فصل قبلی برگردید و درباره «عبور از محدودیتهای ذهن انسان در یادگیری ماشین» بخوانید. در فصل بعدی، توضیح میدهم که شبکه عصبی چطور یاد میگیرد.
نوشتههای روزانه من را درباره محصول، فناوری و کسبوکار در تلگرام دنبال کنید!
دیدگاهتان را بنویسید