
این نوشته، بخشی از کتاب یادگیری ماشین است.
در نوشتههای قبل، با شبکه عمیق آشنا شدیم. آموختیم که این ابزار، ماشین را قادر میسازد تا با ترکیب تعداد زیادی تابع، مدلهایی قدرتمند بسازد. اما اگر داده آموزشی در کار نباشد، از این مدلهای قدرتمند، هیچ کاری بر نمیآید.
یک راه این است که به سراغ دادههای برچسبگذاری شده برویم. در دادههای برچسبگذاری شده، به ازای هر ورودی، میدانیم که خروجی مطلوب چیست. مثلا اگر بخواهیم مدلی بسازیم که نوع پرندگان را شناسایی میکند، به مجموعهای بزرگ از دادههای تصویری نیاز داریم در آنها، از قبل مشخص باشد که هر عکس، متعلق به کدام پرنده است. این همان چیزی است که در «یادگیری با نظارت» به آن پرداختیم.
مشکل اینجاست که بیشتر دادههای در دسترس ما، برچسبگذاری نشدهاند؛ تمام متنها، تمام عکسهای موجود در اینترنت، ویدیوها و پادکستها، هیچکدام برچسب مشخصی ندارند. چطور میشود از این دریای عظیم، برای آموزش مدلها استفاده کرد؟
باید از دادهها به شکلی استفاده کنیم که نیاز به برچسبگذاری از بین برود. مثلا فرض کنید تعداد زیادی «جدول» حل شده به ما بدهند. میتوانیم «شرح جدول» را به ماشین بدهیم و از آن بخواهیم خانههای خالی را پر کند. با توجه به اینکه جدول از قبل حل شده، ماشین میتواند حدسهایش را با پاسخهای جدول مقایسه کند.

در مثال بالا، «شرح جدول» به لایه ورودی شبکه عمیق تحویل داده میشود و از ماشین انتظار میرود در لایه خروجی، به پاسخ جدول دست یابد. به این شیوه از آموزش به مدلها، یادگیری خودنظارتی میگویند. در یادگیری خودنظارتی، به جای دادههای برچسبگذاری شده، مدل باید با اتکا به دادههای بدون برچسب، یاد بگیرد.
البته مثال بالا کمی غلطانداز است؛ چرا که جداول حل شده، شبیه به دادههای برچسبگذاری شده هستند. در ادامه به یکی از مثالهای پرکاربرد یادگیری خودنظارتی اشاره خواهم کرد.
شبکههای خودرمزگذار یا Autoencoders
وقتی یک والد با کودک خود بازی میکند، چیزی شبیه به «یادگیری با نظارت» اتفاق میافتد. کودک با اسباببازیها و محیط پیرامون تعامل برقرار میکند و والد روی یادگیری کودک، نظارت دارد. اما اگر والد فقط شیوه بازی کردن را به کودک یاد دهد و کودک را با اسباببازیهایش تنها بگذارد، چیزی شبیه به یادگیری خودنظارتی اتفاق میافتد.
در واقع اینجا «قواعد بازی» هستند که به کودک کمک میکنند حین یادگیری، از اشتباه کردن پرهیز کند. بنابراین، وقتی میخواهیم یک مدل از دادههای بدون برچسب، یاد بگیرد، باید قواعد بازی را برایش مشخص کنیم.
شبکههای خودرمزگذار، نوعی شبکه عصبی هستند که «قاعده بازی» آنها ساده است: آنها باید در مرحله اول، عصاره دادهها را بگیرند؛ یعنی با کاهش ابعاد داده، آن را فشرده کنند. در مرحله دوم باید دادههای فشرده شده را دوباره به حالت اول برگردانند. همین قاعده ساده، آنها را از وجود دادههای برچسبگذاری شده بینیاز میکند.
در نگاه اول، این کار ممکن است بیهوده به نظر برسد. چرا باید ماشین دادهها را فشرده کرده و سپس به حالت اول باز گردانند؟ ما میخواهیم با این کار، راهی برای تعامل سازنده ماشین با دادهها بسازیم. این تعامل، باعث «یادگیری» ماشین میشود: اگر یک ماشین بتواند دادههای فشرده شده را به حالت اول بازگرداند، یعنی به قواعد حاکم بر آن دادهها مسلط شده است.
مثلا میتوانیم به یک شبکه عصبی، عکسهای با کیفیت بدهیم. در مرحله اول، اندازه عکسها را کاهش داده، آنها را سیاهوسفید کنیم و کیفیت آنها را پایین بیاوریم. در مرحله دوم، شبکه را وادار کنیم عکسهای با کیفیت را از روی عکسهای بیکیفیت بازتولید کند. این کار باعث میشود که شبکه، راه و رسم رنگی کردن عکسها را یاد بگیرد.
شبکه خودرمزگذار چگونه کار میکند؟
همانطور که شرح دادم، شبکه خودرمزگذار، در دو مرحله با دادهها تعامل دارد: مرحله اول، رمزگذاری یا encode نام دارد. اگر طول بردار دادههای ورودی شبکه عصبی، مثلا ۱۰٫۰۰۰ باشد، شبکه باید در این مرحله عصاره دادهها را در بردار کوچکتری، مثلا به طول ۵۰ نگه دارد.
ما نمیدانیم که شبکه چه ویژگیهایی از دادهها را برای عصارهگیری انتخاب میکند. به عبارت دیگر، معنای اعدادی که در خروجی ظاهر میشوند، بر ما پوشیده است. این توجیه خوبی است برای اینکه به خروجی مرحله رمزگذاری، بگوییم «بردار نهفته» یا Latent Vector.
به طور کلی وقتی در یادگیری ماشین، از فضای نهفته یا Latent Space صحبت میشود، منظور فضایی است که در آن، ماشین ویژگیهای معنادار و مهمی از دادهها را نگه داشته، اما دلیل انتخاب یا معنای آنها بر ما پوشیده است.
در مرحله دوم، شبکه خودرمزگذار بردار نهفته را رمزگشایی میکند؛ براساس این بردار، دادههای ورودی بازتولید میشوند. مرحله رمزگذاری و رمزگشایی، دو مرحله مستقل نیستند. برعکس، این دو مرحله در فرایند آموزش بارها و بارها پشت سر هم تکرار میشوند تا مدل بتواند دادههای ورودی را در خروجی شبکه عصبی دوم، بازتولید کند.
در شبکههای خودرمزگذار، کار «تابع زیان» این است که خروجی شبکه را با دادههای ورودی مقایسه کند. اگر اختلاف این دو اندک باشد، یعنی ماشین به خوبی عصاره دادهها را گرفته و سپس توانسته آن را به حالت اولیه بازگرداند. در غیر این صورت، ماشین باید یادگیری را ادامه دهد. در فرایند یادگیری، «گرادیان کاهشی» مثل یک قطبنما عمل میکند؛ اگر اختلاف خروجی شبکه با دادههای ورودی زیاد باشد، گرادیان کاهشی وزنهای شبکه را طوری تغییر میدهد که اختلاف کاهش یابد.
تبدیل واژه به بُردار
در نوشته قبلی، از ضرورت صحبت به زبان ماشینها نوشتم. همچنین شرح دادم که برای خلق مترجمی که میتواند متن را به عدد و عدد را به متن تبدیل کند، باید دستبهدامان ماشینها شویم. حالا که با شبکههای خودرمزگذار آشنا شدهایم، ساختن این مترجم، دیگر شبیه به رویاپردازی نیست.
در نوشته قبل، همچنین شرح دادم که مترجم موردنظر ما، باید کلمات را به ویژگیهای کلیدیشان تجزیه کند. وقتی در مرحله encode یا رمزگذاری، از شبکهخودرمزگذار میخواهیم که دادههای ورودی را در بردار کوچکتری فشرده کند (مثلا ۱۰٫۰۰۰←۵۰)، چنین اتفاقی رخ میدهد.
اگر به شما بگویند نوشته حاضر را در سه کلمه خلاصه کنید، احتمالا سراغ واژههایی نظیر خودنظارتی، خودرمزگذار و شبکه عصبی میروید. محدودیت سه کلمه، تا حد زیادی حق انتخاب را از شما میگیرد.
از آن جایی که بردار خروجی مرحله رمزگذاری، فضای بسیار محدودی دارد، شبکه عصبی هم مجبور است به ویژگیهای کلیدی بسنده کند. در غیر این صورت، نمیتواند در مرحله رمزگشایی، «بردار نهفته» را دوباره به متن تبدیل کند.
تصویر زیر، معماری یک شبکه عصبی خودرمزگذار را نشان میدهد. ورودی این شبکه، یک بردار – زرد رنگ – بسیار بزرگ است؛ طول این بردار به تعداد کلماتی بستگی دارد که مترجم پشتیبانی میکند. در میانه تصویر، «نمایش برداری واژه» با رنگ خاکستری نشان داده شده است. طول این بردار بسیار کوچکتر از ورودی است.
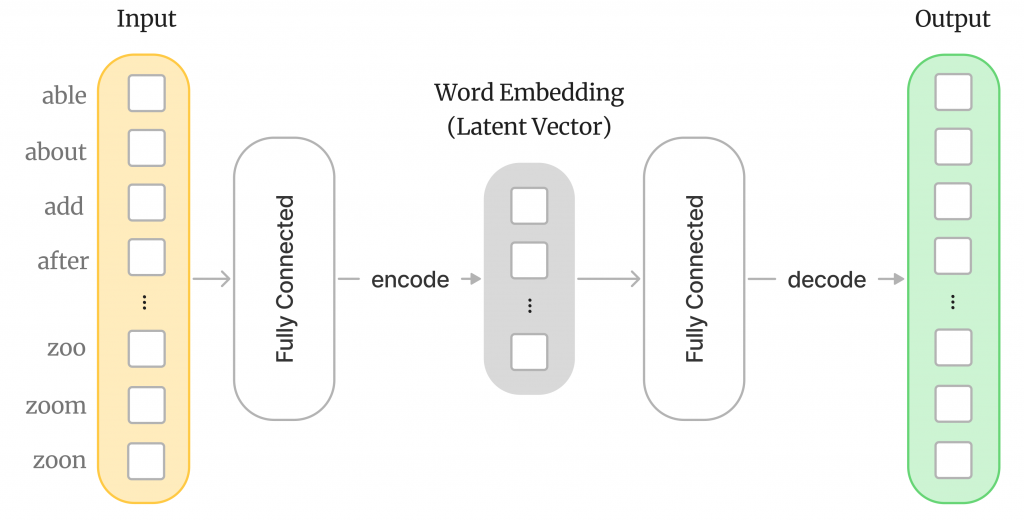
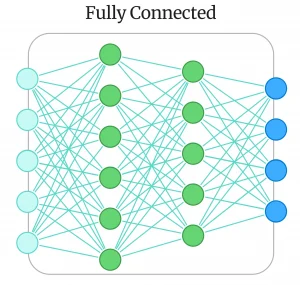
در خروجی شبکه خودرمزگذار، بردار بزرگ سبز رنگی قرار دارد که نشان میدهد در انتها، شبکه خودرمزگذار اعداد را به واژهها برمیگرداند. در قلب این شبکه خودرمزگذار، دو شبکه عصبی Fully Connected قرار دارد. منظور از شبکه Fully Connected یا تماممتصل، شبکهای است که همه نورونهای آن در دو لایه مجاور، به هم متصل هستند.
شبکه تماممتصل اول، مرحله رمزگذاری یا encode را انجام میدهد و شبکه دوم، مرحله رمزگشایی را. تصویر زیر، یک شبکه تماممتصل را نشان میدهد. خیلی وقتها شبکه تماممتصل را به اختصار، با FCN نمایش میدهند.
روش word2vec
همانطور که بالاتر اشاره کردم، «یادگیری خودنظارتی» شبیه به کودکی میماند که با اسباببازیهایش تنها گذاشته شده است. والد قبل از ترک کردن فرزند، قواعد بازی را به او یاد میدهد. همچنین شرح دادم که در یک شبکه خودرمزگذار، قاعده بازی این است: «دادههای ورودی را طوری فشرده کن که بتوانی از روی بردار نهفته، دوباره آن را بازیابی کنی».
اگر دقیقتر به مسئله نگاه کنیم، در مییابیم که این قاعده بازی برای ساخت یک مترجم جوابگو نیست. ما انتظار داریم مترجم، روابط معنایی واژهها را یاد بگیرد. اگر یک واژه را وارد شبکه کنیم و در طرف دیگر، همان واژه را تحویل بگیریم، روابط بین واژهها گم میشود. از طرفی، ما میخواهیم از دادههای متنی در دسترس استفاده کنیم، دادههایی که برچسبگذاری نشدهاند.
به همین خاطر، ناگزیر هستیم که قاعده بازی را تغییر دهیم؛ به گونهای که ساخت یک مترجم امکانپذیر شود.
میدانیم که در یک جمله، بین واژههایی که در نزدیکی یکدیگر قرار دارند، ارتباط معنایی وجود دارد. مثلا در جمله «هوا برفی است و مرطوب»، «هوا و مرطوب» در مجاورت «برفی» قرار دارند. این واژهها میتوانند تا حدی واژه «برفی» را توصیف کنند؛ به عبارت دیگر، «زمینه» آن را مشخص میکنند.
بنابراین میتوانیم از دادههای متنی موجود در اینترنت، برای آموزش یک مدل استفاده کنیم. به این صورت که یک واژه را به عنوان ورودی به شبکه بدهیم و از شبکه بخواهیم «زمینه» یا context واژه را حدس بزند؛ در اینجا منظورمان از زمینه، همان واژههای مجاور است.
روش word2vec، یکی از روشهایی است که از مجاورت واژهها، برای آموزش شبکه استفاده میکند. به طور خلاصه، قاعده بازی word2vec به این صورت است:
- پنجرهای به طول n را روی جملات یک متن بغلتان. مثلا اگر n = 5 باشد، در هر بار ۵ کلمه انتخاب میشود. این روش سادهای است برای این که از دل یک متن، پنج کلمه را که در مجاورت هم قرار دارند، انتخاب کنیم.
- هر بار که ۵ کلمه را انتخاب کردی، کلمه وسط پنجره را به عنوان ورودی به شبکه خودرمزگذار بده (مرحله رمزگذاری).
- شبکه را وادار کن کلمات مجاور را (۴ کلمه باقیمانده) را در خروجی حدس بزند (مرحله رمزگشایی).
در نتیجه تغییر قاعده بازی، شبکه ما دیگر واقعا یک شبکه خودرمزگذار نیست. اما بسیار به آن شبیه است.
در تصویر زیر، ما لحظهای را میبینیم که پنجره نارنجیرنگِ غلتان، به عبارت «powerful automation tool that investors» رسیده است. واژه tool (واژه وسط) به عنوان ورودی به شبکه خورانده شده و انتظار میرود شبکه کلمات مجاور آن را حدس بزند. این روند برای تعداد زیادی جمله، تکرار میشود.
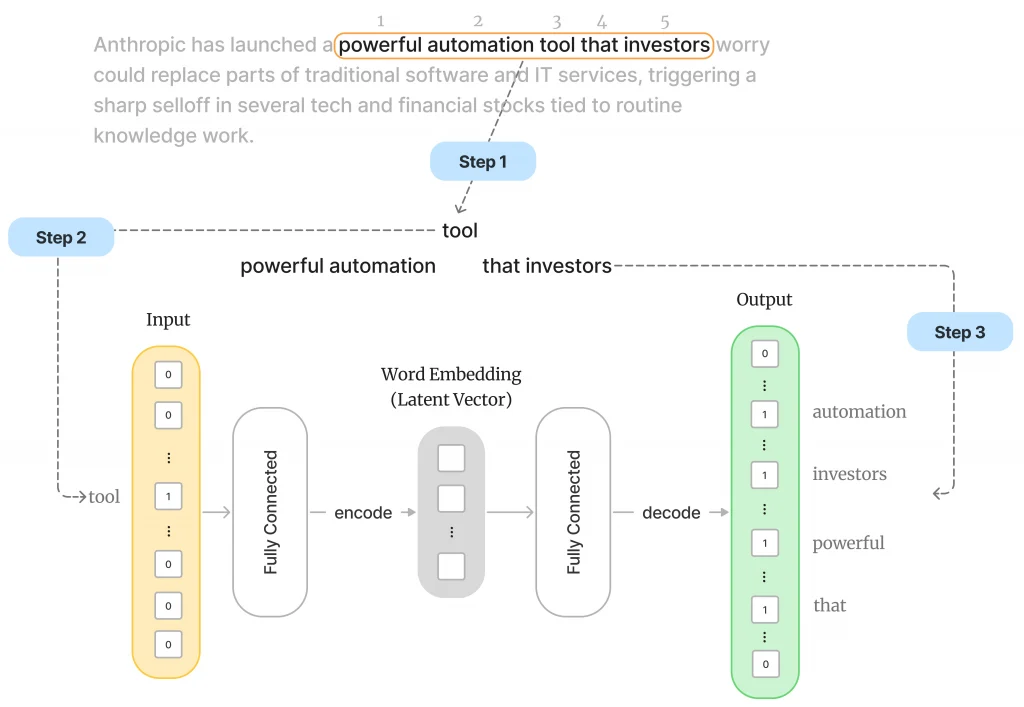
اگر شبکه، واژههای مجاور را اشتباه حدس بزند، «تابع زیان» آن را جریمه میکند. گرادیان کاهشی، با هدف کاهش جریمه، وزنهای شبکه را به گونهای بهروز میکند که شبکه به سمت پاسخهای درست حرکت کند. هر جمله در دادههای آموزشی، یک قدم مترجم را به شناخت واژهها نزدیکتر میکند.
در نهایت، نمایش برداری واژهها – در بردار نهفتهای که بالاتر با رنگ خاکستری نمایش دادم – ذخیره میشود. شبیه به یک شبکه خودرمزگذار، در اینجا هم مترجم مجبور است به خاطر کمبود ظرفیت بردار، فقط ویژگیهای کلیدی واژهها را در نمایش برداریشان ذخیره کند. در غیر این صورت، قادر نخواهد بود در مرحله رمزگشایی، کلمات مجاور را حدس بزند.
بعد از اینکه با میلیونها جمله، شبکه را آموزش دادیم، میتوانیم بخش decoder شبکه را دور بینداریم. حالا اگر به encoder یک واژه بدهیم، نمایش برداری یا نسخه فشرده شده آن را به ما تحویل میدهد؛ این نمایش برداری، حاصل آموزش شبکه با میلیونها واژهای است که در جملات مختلف، در مجاورت هم قرار گرفتهاند.
البته word2vec، فقط یکی از روشهای ترجمه واژهها به اعداد است. خوشبختانه، آشنایی با همین روش کافی است تا ذهنیتی از نحوه تعامل ماشینها با زبان انسانها داشته باشیم. حالا ما قادر هستیم واژهها را – با حفظ روابط معناییشان – به ماشینها بسپاریم. این دریچهای به سوی صدها هزار فرصت به روی انسان باز میکند.
کلیدواژههای مهم
بعد از خواندن این مطلب، سعی کنید این کلیدواژهها را به خاطر بسپارید:
- خودرمزگذار | Autoencoder
- فضای نهفته | Latent space
- بردار نهفته | Latent vector
- معماری شبکه | Network architecture
- یادگیری خودنظارتی | Self-supervised learning
- Word2vec
این نوشته بخشی از «کتاب یادگیری ماشین» است که برای مدیر محصولها و سایر افراد غیرفنی نوشته شده است. فهرست کتاب را در اینجا ببینید.
همچنین میتوانید به فصل قبلی کتاب برگردید و درباره ضرورت تبدیل واژهها به اعداد بخوانید.
نوشتههای روزانه من را درباره محصول، فناوری و کسبوکار در تلگرام دنبال کنید!
دیدگاهتان را بنویسید