
این نوشته، بخشی از کتاب یادگیری ماشین است.
در نوشتههای قبل، با انواع مختلفی از مدلها آشنا شدیم. بعضی از آنها بدون نظارت یاد میگرفتند و برخی دیگر، با نظارت. با وجود اینکه هر مدل هوش مصنوعی، ویژگیهای منحصر به فرد خود را دارد، همه مدلها در یک زمینه اشتراک دارند: آنها به زبان اعداد صحبت میکنند.
مثلا در نوشته قبل دیدیم که یک شبکه عصبی، چطور اعداد را پردازش میکند و به اصطلاح، یاد میگیرد. یا در مثال پیشبینی فروش بستنی، دیدیم که مدل چطور دمای هوا را به عنوان ورودی میپذیرد و تعداد فروش را تخمین میزند.
برای اینکه محدوده توانایی مدلها را وسیعتر کنیم، باید آنها را قادر سازیم تا انواع دیگری از دادها را هم پردازش کنند. اما اکنون میدانیم که مدلها، چیزی جز مجموعهای از توابع ریاضی درهمتنیده نیستند. بنابراین، این ما هستیم که باید زبان ماشینها را بپذیریم؛ آنها در این باره هیچ انعطافی از خود نشان نخواهند داد.
سرراستترین راهحلی که به ذهن میرسد، استفاده از یک مترجم است؛ مترجمی که مثلا بتواند واژهها یا حتی تصاویر را بگیرد و آنها را به عدد ترجمه کند. یا از آن طرف، مترجمی دیگر باید بتواند اعداد را به واژههایی که برای انسان قابلفهم است، برگرداند.
محققان سالها تلاش کردند تا چنین مترجمی را خلق کنند. راهحلهای اولیه، بسیار ساده بودند. یکی از این روشها، Bag of Words نام دارد. در این روش، رشتهای بلند از «صفر و یک» ساخته میشود که در آن، هر کلمه یک نماینده دارد. مثلا اگر زبانی که از آن استفاده میکنیم، ۵۰۰ کلمه داشته باشد، در این روش، رشتهای به طول ۵۰۰ ساخته میشود که همگی «صفر و یک» هستند.

هر کدام از این صفر و یکها (مربعها)، نماینده یک کلمه است. مثلا مربع اول میتواند نماینده کلمه air باشد و مربع آخر، نماینده zebra:
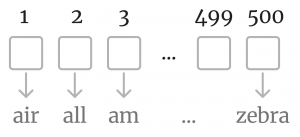
در این روش، هر واژه شبیه به یک کلید خاموش/روشن عمل میکند؛ یعنی اگر یک جمله یا یک مقاله حاوی کلمه air باشد، در مربع اول «یک» قرار میگیرد، در غیر این صورت، «صفر». اگر بخواهیم کل یک مقاله را به زبان اعداد ترجمه کنیم، به ازای تمام کلمات موجود در آن، مربعها را با «یک» پر میکنیم. در سایر مربعها «صفر» قرار میدهیم.
یکی از محدودیتها این است که اگر کلمات درون مقاله جابهجا شود، «ترجمه عددی» آن تغییری نمیکند. در واقع، جای کلمات در نوشته، برای مترجم ما اهمیتی ندارد. همچنین مترجم قادر نیست ارتباط معنایی بین واژهها را در خروجی منعکس کند. اینکه رقم اول نماینده واژه air باشد، صرفا یک قرارداد است؛ یک ترجمه واقعی نیست.
در واقعیت، یک زبان حاوی صدها هزار کلمه است. بنابراین طول رشته ما بسیار طولانی میشود. از نقاط ضعف Bag of Words این است که در اکثر اوقات، بیشتر مربعها «صفر» هستند؛ زیرا یک مقاله، تعداد بسیار محدودی کلمه دارد. ما مجبور میشویم سایر مربعها را با «صفر» پر کنیم که این باعث هدر رفتن حافظه ماشینها میشود.
با وجود این نقاط ضعف، حتی همین روش ساده هم برای حل برخی از مسائل، کار میکند. مثلا با این روش، میشود مدلی را آموزش داد که یک مقاله را میگیرد و دستهبندی آن را مشخص میکند. برای آموزش این مدل، به تعداد زیادی مقاله نیاز داریم که دستهبندی آن مشخص شده باشد. هر مقاله، تبدیل به رشتهای طولانی از اعداد شده و برای آموزش شبکه عصبی استفاده میشود. پس از آموزش مدل، میتوانیم مقالات جدید را به روش Bag of Words به مدل بدهیم و انتظار داشته باشیم که مدل، دسته درست را از بین دستههای موجود انتخاب کند.
نمایش بُرداری واژهها | Word Embeddings
همانطور که دیدیم، Bag of Words روشی ساده و با کارآمدی محدود است که همه نیازهای ما را برآورده نمیکند. اما یک مترجم خوب، چگونه باید باشد؟ بیایید چشانمان را ببندیم و درباره انتظاراتمان از یک مترجم خوب، رویاپردازی کنیم. ما میخواهیم مترجم ایدهآل ما هر کلمه را به بردار تبدیل کند؛ برداری که ویژگیهای معنایی واژه را در خود نگه داشته است.
در ادامه این رویاپردازی، مترجمی را تصور کنید که هر واژه را به عناصر و ویژگیهای کلیدی آن تجزیه میکند. سپس برای هر واژه، یک بردار میسازد و آن را با ویژگیهای کلیدی واژه پر میکند. این کار باعث میشود بردار واژههای مترادف، شبیه به یکدیگر شوند.
مثلا اگر واژه pencil را تجزیه کنیم، به تعداد زیادی ویژگی کلیدی میرسیم. ممکن است ویژگی فرضی a، مشخص کند که «مداد» ابزاری برای نوشتن است. یا ویژگی فرضی b، مشخص کند که اثر مداد را میشود از روی کاغذ، پاک کرد. با این اوصاف، میشود از ویژگی a برای توصیف واژه خودکار یا pen هم استفاده کرد. اما از ویژگی b، به احتمال زیاد برای توصیف خودکار استفاده نمیشود.
اگر ترجمه عددی واژهها را – که از این پس به آنها نمایش برداری واژهها میگوییم – داشته باشیم، میتوانیم آنها در یک فضای n-بعدی ترسیم کنیم. انتظار داریم واژههای مرتبط، نزدیک به یکدیگر ظاهر شوند. برای اینکه این فضا را بهتر درک کنید، تصور کنید هر بردار، شبیه به طول و عرض جغرافیایی یک نقطه از زمین باشد. اگر به آن ناحیه از زمین بروید، واژههایی را در آن نزدیکی میبینید که با واژه منتخب شما ارتباط دارند.
مثلا واژه «سرد»، ما را به ناحیهای میبرد که در نزدیکی آن، شاهد واژههایی نظیر «زمستان، گرم، خشک، خیس و …» خواهیم بود. این واژهها الزاما مترادف یا متضاد یکدیگر نیستند؛ اما به ارتباط معنایی تنگاتنگی دارند. بنابراین، انتظار نداریم در نزدیکی واژه سرد، مثلا واژه «قیف» ظاهر شود.
اما در واقعیت، چطور میشود چنین مترجمی را ساخت؟ ما انسانها قادر به تجزیه صدها هزار کلمه به اجزای کلیدی آنها نیستیم. حتی دقیق نمیدانیم هر کلمه توسط چه ویژگیهایی توصیف میشود. بنابراین راهی جز این نداریم که دست به دامن خود ماشینها شویم. خوشبختانه، اکنون به ابزار قدرتمند «شبکه عصبی» مجهز هستیم؛ شبکهای که میتواند ارتشی عظیم از توابع ریاضی را برای حل مسائل مختلف به کار بگیرد.
کلیدواژههای مهم
بعد از خواندن این مطلب، سعی کنید این کلیدواژه را به خاطر بسپارید:
- نمایش برداری واژهها | Word Embeddings
نوشته حاضر، بخشی از «کتاب یادگیری ماشین» است که برای مدیر محصولها یا افراد غیرفنی نوشته شده است. فهرست این کتاب را در اینجا ببینید.
در فصل بعدی کتاب، ابتدا به «یادگیری خودنظارتی» خواهم پرداخت و سپس درباره نحوه ساخت این مترجم رویایی صحبت خواهم کرد. میتوانید به فصل قبلی بروید و با نحوه یادگیری شبکه عصبی آشنا شوید.
نوشتههای روزانه من را درباره محصول، فناوری و کسبوکار در تلگرام دنبال کنید!
دیدگاهتان را بنویسید